On Roger Sessions’ LinkedIn group, Simpler IT, the discussion “What do I mean by Simplifying” talks about finding simple solutions to problems. Roger’s premise is that every problem has its own inherent complexity:
Let’s say P is some problem that we need to solve. For example, P could be the earthquake in Tom’s example or P could be the need of a bank to process credit cards or P could be my car that needs its oil changed. P may range in complexity from low (my car needs its oil changed) to high (a devastating earthquake has occurred.)
For a given P, the complexity of P is a constant. There is no strategy that will change the complexity of P.
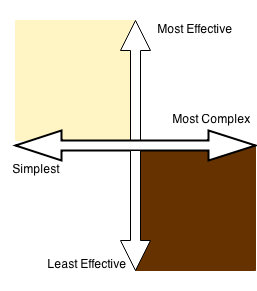
Roger goes on to say that for any given problem, there will be a set of solutions to that problem. He further states “…if P is non-trivial, then the cardinality of the solution set of P is very very large”. Each solution can be characterized by how well it solves the problem at hand and how complex the solution is. These attributes can be graphed, as in the image to the right, yielding quadrants that range from the most effective and least complex (best) to least effective and most complex (worst). Thus, simplifying means:
The best possible s in the solution set is the one that lives in the upper left corner of the graph, as high on the Y axis as possible and as low on the X axis as possible.
When I talk about simplifying, I am talking about finding that one specific s out of all the possible solutions in the solution set.
Simplification, as a strategy, makes a great deal of sense in my opinion. There is, however, another aspect to be considered. While the complexity of a given problem P is constant, P represents the problem space of a system at a given time, not the entire lifecycle. The lifecycle of a system will consist of a set of problem spaces over time, from first release to decommissioning. An architect must take this lifecycle into consideration or risk introducing an ill-considered constraint on the future direction of the product. This is complicated by the fact that there will be uncertainty in how the problem space evolves over time, with the uncertainty being the greatest at the point furthest from the present (as represented by the image below).
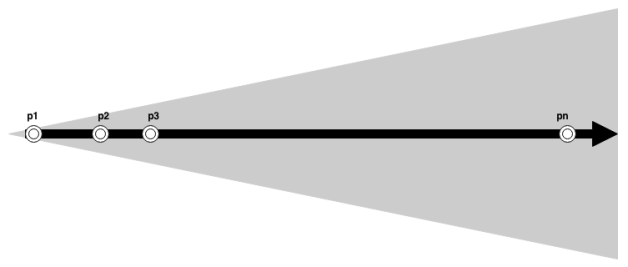
Some information regarding the transition from one problem space to the next will be available. Product roadmaps and deferred issues provide some insight into what will be needed next. That being said, emergent circumstances (everything from unforeseen changes in business direction to unexpected increases in traffic) will conspire to prevent the trajectory of the set of problem spaces from being completely predictable.
Excessive complexity will certainly constrain the options for evolving a system. However, flexibility can come with a certain amount of complexity as well. The simplest solution may also complicate the evolution of a system.



